Continuous Time Markov Decision Process With Finite Horizon
Author: Eric Berg (eb645) (SysEn 5800 Fall 2020)
Introduction
A Markov Decision Process (MDP) is a stochastic sequential decision making method. Sequential decision making is applicable any time there is a dynamic system that is controlled by a decision maker where decisions are made sequentially over time. MDPs can be used to determine what action the decision maker should make given the current state of the system and its environment. This decision making process takes into account information from the environment, actions performed by the agent, and rewards in order to decide the optimal next action. MDPs can be characterized as both finite or infinite and continuous or discrete depending on the set of actions and states available and the decision making frequency. This article will focus on discrete MDPs with finite states and finite actions for the sake of simplified calculations and numerical examples. The name Markov refers to the Russian mathematician Andrey Markov, since the MDP is based on the Markov Property. In the past, MDPs have been used to solve problems like inventory control, queuing optimization, and routing problems. Today, MDPs are often used as a method for decision making in the reinforcement learning applications, serving as the framework guiding the machine to make decisions and "learn" how to behave in order to achieve its goal.


Theory and Methodology
A MDP makes decisions using information about the system's current state, the actions being performed by the agent and the rewards earned based on states and actions.
The MDP is made up of multiple fundamental elements: the agent, states, a model, actions, rewards, and a policy. The agent is the object or system being controlled that has to make decisions and perform actions. The agent lives in an environment that can be described using states, which contain information about the agent and the environment. The model determines the rules of the world in which the agent lives, in other words, how certain states and actions lead to other states. The agent can perform a fixed set of actions in any given state. The agent receives rewards based on its current state. A policy is a function that determines the agent's next action based on its current state.
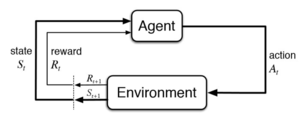
Reinforcement Learning framework used in Markov Decision Processes
MDP Framework:
In order to understand how the MDP works, first the Markov Property must be defined. The Markov Property states that the future is independent of the past given the present. In other words, only the present is needed to determine the future, since the present contains all necessary information from the past. The Markov Property can be described in mathematical terms below:

![{\textstyle P[S_{t+1}|S_{t}]=P[S_{t+1}|S_{1},S_{2},S_{3}...S_{t}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/75ef438d698845bb28d52f2e38468979d654bbfc)
The above notation conveys that the probability of the next state given the current state is equal to the probability of the next state given all previous states. The Markov Property is relevant to the MDP because only the current state is used to determine the next action, the previous states and actions are not needed.
The Policy and Value Function
The policy, , is a function that maps actions to states. The policy determines which is the optimal action given the current state to achieve the maximum total reward.


Before the best policy can be determined, a goal or return must be defined to quantify rewards at every state. There are various ways to define the return. Each variation of the return function tries to maximize rewards in some way, but differs in which accumulation of rewards should be maximized. The first method is to choose the action that maximizes the expected reward given the current state. This is the myopic method, which weighs each time-step decision equally. Next is the finite-horizon method, which tries to maximize the accumulated reward over a fixed number of time steps. But because many applications may have infinite horizons, meaning the agent will always have to make decisions and continuously try to maximize its reward, another method is commonly used, known as the infinite-horizon method. In the infinite-horizon method, the goal is to maximize the expected sum of rewards over all steps in the future. When performing an infinite sum of rewards that are all weighed equally, the results may not converge and the policy algorithm may get stuck in a loop. In order to avoid this, and to be able prioritize short-term or long term-rewards, a discount factor, , is added. If is closer to 0, the policy will choose actions that prioritize more immediate rewards, if is closer to 1, long-term rewards are prioritized.


Return/Goal Variations:
- Myopic: Maximize , maximize expected reward for each state
- Finite-horizon: Maximize , maximize sum of expected reward over finite horizon
- Discounted Infinite-horizon: Maximize , maximize sum of discounted expected reward over infinite horizon
![{\displaystyle E[r_{t}|\Pi ,s_{t}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b0e60055aa79932986f8173be33f717efdddd403)
![{\displaystyle E[\textstyle \sum _{t=0}^{k}\displaystyle r_{t}|\Pi ,s_{t}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0a9962569af3b42f6649052cad8b095c044405cc)
![{\displaystyle E[\textstyle \sum _{t=0}^{\infty }\displaystyle \gamma ^{t}r_{t}|\Pi ,s_{t}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c33036669c07e9152791368d2286caaeb734c293)
![{\displaystyle \gamma \epsilon [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5d5a8bd3c5b3887060735b066e88e596b00c0291)
The value function, , characterizes the return at a given state. Most commonly, the discounted infinite horizon return method is used to determine the best policy. Below the value function is defined as the expected sum of discounted future rewards.

![{\displaystyle V(s)=E[\sum _{t=0}^{\infty }\gamma ^{t}r_{t}|s_{t}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1712068d3d05cc2113753d97f5f87cf28083030b)
The value function can be decomposed into two parts, the immediate reward of the current state, and the discounted value of the next state. This decomposition leads to the derivation of the Bellman Equation,, as shown in equation (2). Because the actions and rewards are dependent on the policy, the value function of an MDP is associated with a given policy.
,
![{\displaystyle V(s)=E[r_{t+1}+\gamma V(s_{t+1})|s_{t}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fa310d37a263f2fd50e315a648ddd3b5b5967437)


(1)

(2)
![{\displaystyle V^{*}(s)=max_{a}[R(s,a)+\gamma \sum _{s'\epsilon S}P(s'|s,a)V^{*}(s')]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5fd1f18aa236da93103ce029f563dd81ed809d37)
The optimal value function can be solved iteratively using iterative methods such as dynamic programming, Monte-Carlo evaluations, or temporal-difference learning.

The optimal policy is one that chooses the action with the largest optimal value given the current state:
(3)
![{\displaystyle \Pi ^{*}(s)=argmax_{a}[R(s,a)+\gamma \sum _{s'\epsilon S}P_{ss'}^{a}V(s')]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a3d6a9516a05668788d40f60502a9102c386c05e)
The policy is a function of the current state, meaning at each time step a new policy is calculated considering the present information. The optimal policy function can be solved using methods such as value iteration, policy iteration, Q-learning, or linear programming.

Algorithms
The first method for solving the optimality equation (2) is using value iteration, also known as successive approximation, backwards induction, or dynamic programming.

Value Iteration Algorithm:
- Initialization: Set for all , choose , n=1
- Value Update: For each , compute:
- If , the algorithm has converged and the optimal value function, , has been determined, otherwise return to step 2 and increment n by 1.



![{\displaystyle V_{n+1}^{*}(s)=max_{a}[R(s,a)+\gamma \sum _{s'\epsilon S}P(s'|s,a)V_{n}^{*}(s')]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/71953fa22490ea1dc997121602dc6746b3f23ddf)


The value function approximation becomes more accurate at each iteration because more future states are considered. The value iteration algorithm can be slow to converge in certain situations, so an alternative algorithm can be used which converges more quickly.
Policy Iteration Algorithm:
- Initialization: Set an arbitrary policy and for all , choose , n=1
- Policy Evaluation: For each , compute:
- If , the optimal value function, has been determined, continue to next step, otherwise return to step 2 and increment n by 1.
- Policy Update: For each , compute:
- If ,the algorithm has converged and the optimal policy, has been determined, otherwise return to step 2 and increment n by 1.


![{\displaystyle \Pi _{n+1}(s)=argmax_{a}[R(s,\Pi _{n}(s))+\gamma \sum _{s'\epsilon S}P(s'|s,\Pi _{n}(s))V_{n}^{\Pi }(s')]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/39b3cf8fa3cecc2e6a7e77dd77e0ba82d9c4a49d)


With each iteration the optimal policy is improved using the previous policy and value function until the algorithm converges and the optimal policy is found.
Numerical Example
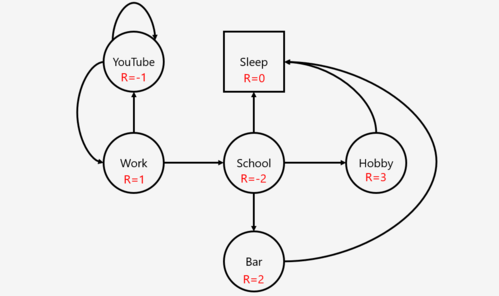
A Markov Decision Process describing a college student's hypothetical situation.
As an example, the MDP can be applied to a college student, depicted to the right. In this case, the agent would be the student. The states would be the circles and squares in the diagram, and the arrows would be the actions. The action between work and school is leave work and go to school. In the state that the student is at school, the allowable actions are to go to the bar, enjoy their hobby, or sleep. The probabilities assigned to each state given the previous state and action in this example is 1. The rewards associated with each state are written in red.
Assume , =1.

First, the optimal value functions must be calculated for each state.
![{\displaystyle V^{*}(Hobby)=max_{a}[3+(1)(1.0*0)]=3}](https://wikimedia.org/api/rest_v1/media/math/render/svg/384a16f7b7127a8673b75567052b743e67b1526d)
![{\displaystyle V^{*}(Bar)=max_{a}[2+1(1.0*0)]=2}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c90f05e9e3179b004990004cc43dffe05dd0cb57)
![{\displaystyle V^{*}(Sleep)=max_{a}[0+1(1.0*0)]=0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/579e4db00ce342cb09827a3a1b69076d0c0b520a)
![{\displaystyle V^{*}(School)=max_{a}[-2+1(1.0*2),-2+1(1.0*0),-2+1(1.0*3)]=1}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ea94ef137535ffcfbcd83d1e7110262768830a86)
![{\displaystyle V^{*}(YouTube)=max_{a}[-1+1(1.0*-1),-1+1(1.0*1)]=0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/356fe1c9880881d325da16ca8042b5c96e615efe)
![{\displaystyle V^{*}(Work)=max_{a}[1+1(1.0*0),1+1(1.0*1)]=2}](https://wikimedia.org/api/rest_v1/media/math/render/svg/223e66eb50bc5e5851255fbc3508f2d806222bf2)
Then, the optimal policy at each state will choose the action that generates the highest value function.
Work
![{\displaystyle \Pi ^{*}(YouTube)=argmax_{a}[0,2]\rightarrow a=}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c7d6699622ac53c6703f213a77032cf93a0d9590)
School
![{\displaystyle \Pi ^{*}(Work)=argmax_{a}[0,1]\rightarrow a=}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4dada00f7c20fec0de846703db38f042bd423f4b)
Hobby
![{\displaystyle \Pi ^{*}(School)=argmax_{a}[0,2,3]\rightarrow a=}](https://wikimedia.org/api/rest_v1/media/math/render/svg/34f6ff933833b08e879be6c2cf88fc8549bb4286)
Therefore, the optimal policy in each state provides a sequence of decisions that generates the optimal path sequence in this decision process. As a results, if the student starts in state Work, he/she should choose to go to school, then to enjoy their hobby, then go to sleep.
Applications

Computer playing Pong arcade game by Atari using reinforcement learning
MDPs have been applied in various fields including operations research, electrical engineering, computer science, manufacturing, economics, finance, and telecommunication. For example, the sequential decision making process described by MDP can be used to solve routing problems such as the Traveling salesman problem. In this case, the agent is the salesman, the actions available are the routes available to take from the current state, the rewards in this case are the costs of taking each route, and the goal is to determine the optimal policy that minimizes the cost function over the duration of the trip. Another application example is maintenance and repair problems, in which a dynamic system such as a vehicle will deteriorate over time due to its actions and the environment, and the available decisions at every time epoch is to do nothing, repair, or replace a certain component of the system. This problem can be formulated as an MDP to choose the actions that to minimize cost of maintenance over the life of the vehicle. MDPs have also been applied to optimize telecommunication protocols, stock trading, and queue control in manufacturing environments.
Given the significant advancements in artificial intelligence and machine learning over the past decade, MDPs are being applied in fields such as robotics, automated systems, autonomous vehicles, and other complex autonomous systems. MDPs have been used widely within reinforcement learning to teach robots or other computer-based systems how to do something they were previously were unable to do. For example, MDPs have been used to teach a computer how to play computer games like Pong, Pacman, or AlphaGo. DeepMind Technologies, owned by Google, used the MDP framework in conjunction with neural networks to play Atari games better than human experts. In this application, only the raw pixel input of the game screen was used as input, and a neural network was used to estimate the value function for each state, and choose the next action. MDPs have been used in more advanced applications to teach a simulated human robot how to walk and run and a real legged-robot how to walk.




Google's DeepMind uses reinforcement learning to teach AI how to walk
Conclusion
A MDP is a stochastic, sequential decision-making method based on the Markov Property. MDPs can be used to make optimal decisions for a dynamic system given information about its current state and its environment. This process is fundamental in reinforcement learning applications and a core method for developing artificially intelligent systems. MDPs have been applied to a wide variety of industries and fields including robotics, operations research, manufacturing, economics, and finance.
References
- Puterman, M. L. (1990). Chapter 8 Markov decision processes. In Handbooks in Operations Research and Management Science (Vol. 2, pp. 331–434). Elsevier. https://doi.org/10.1016/S0927-0507(05)80172-0
- Feinberg, E. A., & Shwartz, A. (2012). Handbook of Markov Decision Processes: Methods and Applications. Springer Science & Business Media.
- Howard, R. A. (1960). Dynamic programming and Markov processes. John Wiley.
- Ashraf, M. (2018, April 11). Reinforcement Learning Demystified: Markov Decision Processes (Part 1). Medium. https://towardsdatascience.com/reinforcement-learning-demystified-markov-decision-processes-part-1-bf00dda41690
- Bertsekas, D. P. (2011). Dynamic Programming and Optimal Control 3rd Edition, Volume II. Massachusetts Institue of Technology, 233.
- Littman, M. L. (2001). Markov Decision Processes. In N. J. Smelser & P. B. Baltes (Eds.), International Encyclopedia of the Social & Behavioral Sciences (pp. 9240–9242). Pergamon. https://doi.org/10.1016/B0-08-043076-7/00614-8
- Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., & Riedmiller, M. (2013). Playing Atari with Deep Reinforcement Learning. ArXiv:1312.5602 [Cs]. http://arxiv.org/abs/1312.5602
- Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai, M., Guez, A., Lanctot, M., Sifre, L., Kumaran, D., Graepel, T., Lillicrap, T., Simonyan, K., & Hassabis, D. (2018). A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science, 362(6419), 1140–1144. https://doi.org/10.1126/science.aar6404
- Ha, S., Xu, P., Tan, Z., Levine, S., & Tan, J. (2020). Learning to Walk in the Real World with Minimal Human Effort. ArXiv:2002.08550 [Cs]. http://arxiv.org/abs/2002.08550
- Bellman, R. (1966). Dynamic Programming. Science, 153(3731), 34–37. https://doi.org/10.1126/science.153.3731.34
- Abbeel, P. (2016). Markov Decision Processes and Exact Solution Methods: 34.
- Silver, D. (2015). Markov Decision Processes. Markov Processes, 57.
Source: https://optimization.cbe.cornell.edu/index.php?title=Markov_decision_process
0 Response to "Continuous Time Markov Decision Process With Finite Horizon"
Post a Comment